FR
FR JA
JA

Gathering Accurate Location-based Intelligence from Real-world Signals
Location intelligence is a very powerful tool for businesses to understand consumer behavior through real-world signals such as traffic hours, affluence, lifestyle, etc. This actionable intelligence can be used to segment, target, and engage consumers better across categories. Location intelligence also makes it easy to measure the performance of marketing efforts through store footfall attribution.
The volume of location data has increased considerably in the last two decades presenting several challenges with respect to storage, processing, and deriving actionable intelligence. With this exponential increase, standalone computing systems are unable to manage such data with their limited ability to process and analyze at scale. Presently, the few solutions available to process geospatial big data have complex implementation protocols and have a limited integration capability with varied geospatial frameworks.
The Diversity of Geospatial Data
Geospatial data is the core for analyzing the behavior of people and places, and for determining the relationship between the two. Geospatial data consists of information about a place in terms of location and other associated attributes.
Unlike other datasets, it takes only three standard structure forms namely point, line, and polygon.
- A point data stores single coordinate information with other attributes like name, address, etc.
- A line is a series of coordinates to store information of space as well as other attributes of features like road, river, railway track, etc.
- A polygon stores information of a continuous surface in the form of the coordinates that bound it and some other attributes.
The below picture depicts the coexistence of the three data formats with different representations. The point can contain information such as coordinates to place it on a map, the name of the bank it represents, and maybe the address. Similarly, the polygon can provide information on the building name, bank name, number of floors, etc. while, the line can provide information on the name of the road, the width of the road, and whether it is a one-way street, etc.
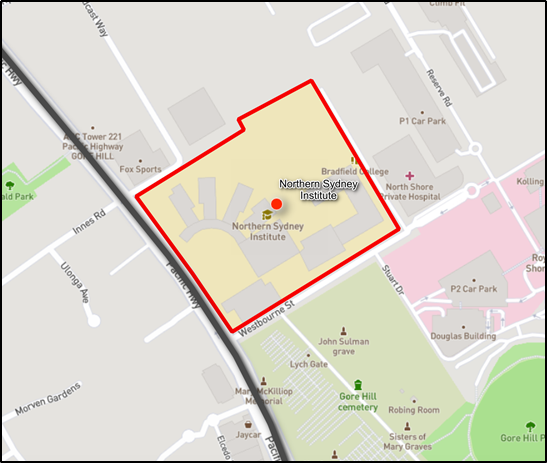
Today, consumers generate a huge amount of information in the form of points representing restaurants, shopping centers, malls, etc. and continuously emit numerous location pings through GPS as they move with their mobile devices. Also, the buildings are not mere points on a map and several polygons may represent a building’s proper shape and area. When working at the geographical level of a country, the size of spatial data and the complexity of data operations exceed the capacity of the current computing systems and dedicated software.
Why Working with Geospatial Data at Scale is a Challenge?
Consider the scenario, where we have these three datasets in different files, and we want to know in which polygon the point of the University falls in and how far is the nearest edge from the road. Once we have the attributes of the polygon associated with it, the area of the University, the distance of the University gate from the road, and other information can be associated easily to the point data. All these operations will require a two-dimensional coordinate geometry solution to find the association between them. This is a daunting task that would take a lot of time and is difficult to parallelize on a distributed computing system.
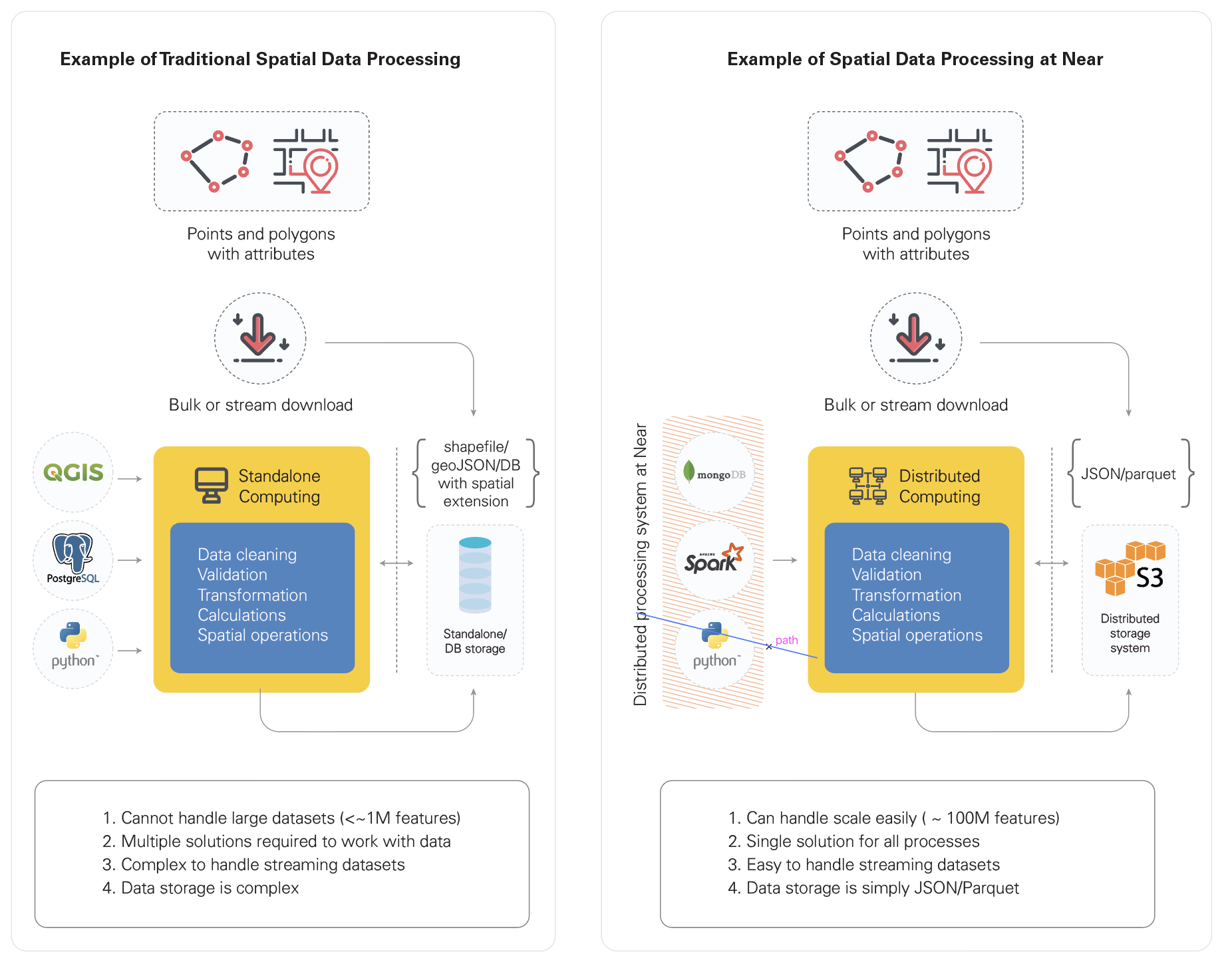
The task becomes uphill with the volume of the data increasing to an extent that it cannot be handled by the dedicated GIS desktop software or GIS working environments on standalone machines. The need of the hour is to come up with flexible and scalable solutions to handle the processing of spatial data. For the past few years, there has been an active development and effort going on to come up with solutions to process and query spatial data quickly and at scale. Some examples of platforms and APIs that allow large-scale geospatial querying and operations are Geospark, Geomesa, and Hadoop-GIS. Also, a greater number of SQL, as well as NoSQL datastores, are now available to provide support from limited to a wide range of spatial queries on geospatial data.
The challenge with the datastores is the scalability of the process. They cannot perform the task given to them parallelly on the data, though they are rich in providing a number of geospatial operations such as spatial joins, distance calculations, spatial overlays, etc. On the other hand, geospatial big data platforms provide a limited number of spatial operations but speed up the process considerably. These platforms also require a unique setup and environment which is not easy to implement and also adds to the cost since you cannot use the existing big data processing platforms like Spark.
How are we Solving the Problem at Azira?
The Azira platform employs the Distributed Computing Framework to manage geospatial big data at scale with flexible integration and configuration. Azira processes more than 10TB of data daily and works with millions of points and polygon data. Constant research & development efforts are made to handle large amounts of such data to meet customer expectations.
The Azira platform leverages the power of distributed computing (Spark) with some effective configuration without affecting the dedicated use of the platform to utilize it to solve the problem of geospatial big data processing. For example, to process a simple proximity analysis using a standard Python environment for finding the nearest polygon from a million points and a few million polygons, it takes several hours. But with the configured Spark environment and use of standard geospatial packages and functions in Python, the same exercise takes about 1/30th the time. The use of a Python environment to define geospatial operation logic provides flexibility (a sandbox) and using Spark in parallel creates a powerful combination. Not just that, it also allows us to integrate the power of datastores like MongoDB and further accelerate the processing speed to a large extent. In another example, calculating the centroids of tens of millions of polygons with distributed computing takes a few minutes while a standalone machine would have taken several hours for the task. We ensure the geometric format is flexible and convertible from text to a shape object and vice versa. Moreover, when working on geospatial data, spatial indexing is extremely important and the Azira platform executes that meticulously.
Deriving Actionable Intelligence is our Day Job
A lot of attention is being given to developing a platform of geospatial big data queries and operations, but a solution that is well settled to be used is still a step away. The existing solutions are not simple to set up nor customizable, but are dedicated to geospatial data and support direct ‘read and write’ operations from its environment.
At Azira, we harness the power of existing big data platforms such as Spark with effective configuration steps to bring in speed and efficiency into the process. Utilizing Python packages and functions to work on the geospatial data within the Python environment and storing the data in the Spark environment in the form of text simplifies the complex task of processing large scale data. This helps us expedite the processing of huge amounts of geospatial data to derive actionable intelligence for our customers.